webalizer是一个高效的、免费的web服务器日志分析程序。其分析结果以HTML文件格式保存,从而可以很方便的通过web服务器进行浏览。webalizer支持标准的一般日志文件格式(Common Logfile Format);除此之外,也支持几种组合日志格式(Combined Logfile Format)的变种,从而可以统计客户情况以及客户操作系统类型。并且现在webalizer已经可以支持wu-ftpd xferlog日志格式以及squid日志文件格式了。支持命令行配置以及配置文件。
下面介绍webalizer的安装:
从webalizer的官方站点下载webalizer,当前的最新版本是2.23-05。
编者这里就直接将下载的webalizer放在/root/目录下了:
首先解开源代码包:
[root@localhost ~]# tar zxvf webalizer-2.23-05-src.tgz

在生成的目录中有个lang目录,该目录中保存了各种语言文件,但是只有繁体中文版本,可以自己转换成简体,或者自己重新翻译一下。
然后在生成的目录:
./configure
make
make install
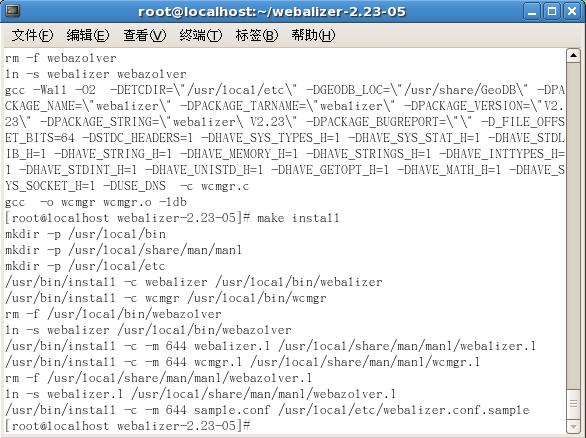
编译成功后,会产生一个webalizer可执行文件,可以将其拷贝到/usr/sbin/目录下:
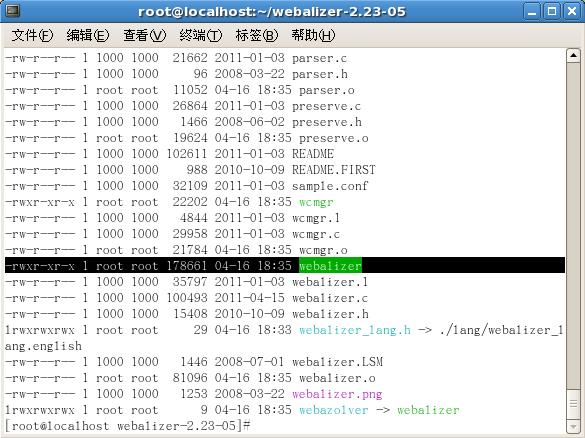
[root@localhost webalizer-2.23-05]# cp webalizer /usr/sbin/
[root@localhost webalizer-2.23-05]#
然后就可以开始配置webalizer了。
配置:
上面说过,可以通过命令行配置webalizer,也可以通过配置文件进行配置,在本文中我们将介绍使用命令行参数进行配置,需要了解配置文件使用方法的朋友可以参考README文件,里面有很详细的介绍。
可以执行webalizer –h得到所有命令行参数:
[root@localhost sbin]# webalizer -h
Usage: webalizer [options] [log file]
-h = print this help message
-V = print version information
-v = be verbose
-d = print additional debug info
-F type = Log type. type= (clf | ftp | squid | w3c)
-f = Fold sequence errors
-i = ignore history file
-p = preserve state (incremental)
-b = ignore state (incremental)
-q = supress informational messages
-Q = supress _ALL_ messages
-Y = supress country graph
-G = supress hourly graph
-H = supress hourly stats
-L = supress color coded graph legends
-l num = use num background lines on graph
-m num = Visit timout value (seconds)
-T = print timing information
-c file = use configuration file 'file'
-n name = hostname to use
-o dir = output directory to use
-t name = report title 'name'
-a name = hide user agent 'name'
-r name = hide referrer 'name'
-s name = hide site 'name'
-u name = hide URL 'name'
-x name = Use filename extension 'name'
-O name = Omit page 'name'
-P name = Page type extension 'name'
-I name = Index alias 'name'
-K num = num months in summary table
-k num = num months in summary graph
-A num = Display num top agents
-C num = Display num top countries
-R num = Display num top referrers
-S num = Display num top sites
-U num = Display num top URLs
-e num = Display num top Entry Pages
-E num = Display num top Exit Pages
-g num = Group Domains to 'num' levels
-X = Hide individual sites
-z dir = Use country flags in 'dir'
-D name = Use DNS Cache file 'name'
-N num = Number of DNS processes (0=disable)
-j = Enable native GeoDB lookups
-J name = Use GeoDB database 'name'
[root@localhost sbin]#
假设,web服务器主机名为www.test.com,统计站点域名为www.test.com, 访问日志为/var/log/httpd/access_log, 我们将webalizer分析结果输出到/var/www/html/log下面。则我们可以建立以下脚本/etc/rc.d/webalizer:
[root@localhost sbin]# vim /etc/rc.d/webalizer
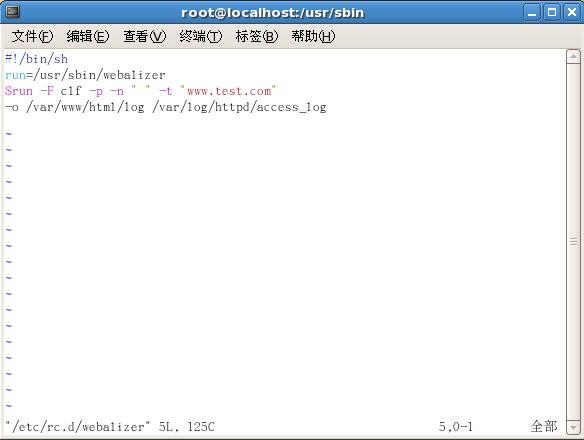
#!/bin/sh
run=/usr/sbin/webalizer
$run -F clf -p -n " " -t "www.test.com"
-o /var/www/html/log /var/log/httpd/access_log
说明:
-F clf 指明我们的web日志格式为标准的一般日志文件格式(Common Logfile Format)
-p 指定使用递增模式,这就是说每作一次分析后,webalizer会生产一个历史文件,这样下一次分析时就可以不分析已经处理过的部分。这样我们就可以在短时间内转换我们的日志文件,而不用担心访问量太大时日志文件无限增大了。
-n “ “ 指定服务器主机名为空,这样输出结果会美观一些。
-o “www.test.com” 指定输出结果标题.
/var/log/httpd/access_log:指定日志文件
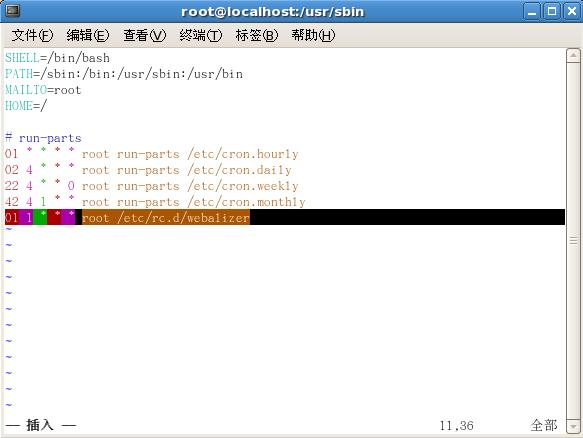
然后在/etc/crontab中加入:
01 1 * * * root /etc/rc.d/webalizer
即每天凌晨1点执行该脚本。
[root@localhost sbin]# vim /etc/crontab
然后运行/etc/rc.d/init.d/crond reload重载入crond服务。
[root@localhost sbin]# /etc/rc.d/init.d/crond reload
重新载入 cron 守护进程配置: &nb
.........................................................